Mean
There are several kinds of means in various branches of mathematics (especially statistics).
For a data set, the arithmetic mean, also called the mathematical expectation or average, is the central value of a discrete set of numbers: specifically, the sum of the values divided by the number of values. The arithmetic mean of a set of numbers x1, x2, ..., xn is typically denoted by x¯{displaystyle {bar {x}}}


In probability and statistics, the population mean, or expected value, are a measure of the central tendency either of a probability distribution or of the random variable characterized by that distribution.[2] In the case of a discrete probability distribution of a random variable X, the mean is equal to the sum over every possible value weighted by the probability of that value; that is, it is computed by taking the product of each possible value x of X and its probability p(x), and then adding all these products together, giving μ=∑xp(x){displaystyle mu =sum xp(x)}
For a finite population, the population mean of a property is equal to the arithmetic mean of the given property while considering every member of the population. For example, the population mean height is equal to the sum of the heights of every individual divided by the total number of individuals. The sample mean may differ from the population mean, especially for small samples. The law of large numbers dictates that the larger the size of the sample, the more likely it is that the sample mean will be close to the population mean.[4]
Outside probability and statistics, a wide range of other notions of "mean" are often used in geometry and analysis; examples are given below.
Contents
1 Types of mean
1.1 Pythagorean means
1.1.1 Arithmetic mean (AM)
1.1.2 Geometric mean (GM)
1.1.3 Harmonic mean (HM)
1.1.4 Relationship between AM, GM, and HM
1.2 Statistical location
1.3 Mean of a probability distribution
1.4 Generalized means
1.4.1 Power mean
1.4.2 ƒ-mean
1.5 Weighted arithmetic mean
1.6 Truncated mean
1.7 Interquartile mean
1.8 Mean of a function
1.9 Mean of angles and cyclical quantities
1.10 Fréchet mean
1.11 Other means
2 Distribution of the sample mean
3 See also
4 References
Types of mean
Pythagorean means
Arithmetic mean (AM)
The arithmetic mean (or simply mean) of a sample x1,x2,…,xn{displaystyle x_{1},x_{2},ldots ,x_{n}}
- x¯=1n(∑i=1nxi)=x1+x2+⋯+xnn{displaystyle {bar {x}}={frac {1}{n}}left(sum _{i=1}^{n}{x_{i}}right)={frac {x_{1}+x_{2}+cdots +x_{n}}{n}}}

For example, the arithmetic mean of five values: 4, 36, 45, 50, 75 is:
- 4+36+45+50+755=2105=42.{displaystyle {frac {4+36+45+50+75}{5}}={frac {210}{5}}=42.}

Geometric mean (GM)
The geometric mean is an average that is useful for sets of positive numbers that are interpreted according to their product and not their sum (as is the case with the arithmetic mean); e.g., rates of growth.
- x¯=(∏i=1nxi)1n=(x1x2⋯xn)1n{displaystyle {bar {x}}=left(prod _{i=1}^{n}{x_{i}}right)^{frac {1}{n}}=left(x_{1}x_{2}cdots x_{n}right)^{frac {1}{n}}}

For example, the geometric mean of five values: 4, 36, 45, 50, 75 is:
- (4×36×45×50×75)15=243000005=30.{displaystyle (4times 36times 45times 50times 75)^{frac {1}{5}}={sqrt[{5}]{24;300;000}}=30.}
![{displaystyle (4times 36times 45times 50times 75)^{frac {1}{5}}={sqrt[{5}]{24;300;000}}=30.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/3b516046ef2a7b8b23301b7ab228cec73f38e062)
Harmonic mean (HM)
The harmonic mean is an average which is useful for sets of numbers which are defined in relation to some unit, for example speed (distance per unit of time).
- x¯=n(∑i=1n1xi)−1{displaystyle {bar {x}}=nleft(sum _{i=1}^{n}{frac {1}{x_{i}}}right)^{-1}}

For example, the harmonic mean of the five values: 4, 36, 45, 50, 75 is
- 514+136+145+150+175=513=15.{displaystyle {frac {5}{{tfrac {1}{4}}+{tfrac {1}{36}}+{tfrac {1}{45}}+{tfrac {1}{50}}+{tfrac {1}{75}}}}={frac {5}{;{tfrac {1}{3}};}}=15.}

Relationship between AM, GM, and HM
AM, GM, and HM satisfy these inequalities:
- AM≥GM≥HM{displaystyle mathrm {AM} geq mathrm {GM} geq mathrm {HM} ,}

Equality holds if and only if all the elements of the given sample are equal.
Statistical location
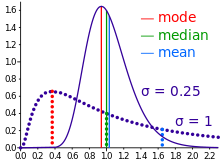
Comparison of the arithmetic mean, median and mode of two skewed (log-normal) distributions.

Geometric visualization of the mode, median and mean of an arbitrary probability density function.[5]
In descriptive statistics, the mean may be confused with the median, mode or mid-range, as any of these may be called an "average" (more formally, a measure of central tendency). The mean of a set of observations is the arithmetic average of the values; however, for skewed distributions, the mean is not necessarily the same as the middle value (median), or the most likely value (mode). For example, mean income is typically skewed upwards by a small number of people with very large incomes, so that the majority have an income lower than the mean. By contrast, the median income is the level at which half the population is below and half is above. The mode income is the most likely income and favors the larger number of people with lower incomes. While the median and mode are often more intuitive measures for such skewed data, many skewed distributions are in fact best described by their mean, including the exponential and Poisson distributions.
Mean of a probability distribution
The mean of a probability distribution is the long-run arithmetic average value of a random variable having that distribution. In this context, it is also known as the expected value. For a discrete probability distribution, the mean is given by ∑xP(x){displaystyle textstyle sum xP(x)}



Generalized means
Power mean
The generalized mean, also known as the power mean or Hölder mean, is an abstraction of the quadratic, arithmetic, geometric and harmonic means. It is defined for a set of n positive numbers xi by
- x¯(m)=(1n∑i=1nxim)1m{displaystyle {bar {x}}(m)=left({frac {1}{n}}sum _{i=1}^{n}x_{i}^{m}right)^{frac {1}{m}}}

By choosing different values for the parameter m, the following types of means are obtained:
m→∞{displaystyle mrightarrow infty }
maximum of xi{displaystyle x_{i}}
m=2{displaystyle m=2}
quadratic mean
m=1{displaystyle m=1}
arithmetic mean
m→0{displaystyle mrightarrow 0}
geometric mean
m=−1{displaystyle m=-1}
harmonic mean
m→−∞{displaystyle mrightarrow -infty }
minimum of xi{displaystyle x_{i}}







ƒ-mean
This can be generalized further as the generalized ƒ-mean
- x¯=f−1(1n∑i=1nf(xi)){displaystyle {bar {x}}=f^{-1}left({{frac {1}{n}}sum _{i=1}^{n}{fleft(x_{i}right)}}right)}

and again a suitable choice of an invertible ƒ will give
f(x)=x{displaystyle f(x)=x}
arithmetic mean,
f(x)=1x{displaystyle f(x)={frac {1}{x}}}
harmonic mean,
f(x)=xm{displaystyle f(x)=x^{m}}
power mean,
f(x)=ln(x){displaystyle f(x)=ln(x)}
geometric mean.




Weighted arithmetic mean
The weighted arithmetic mean (or weighted average) is used if one wants to combine average values from samples of the same population with different sample sizes:
- x¯=∑i=1nwixi∑i=1nwi.{displaystyle {bar {x}}={frac {sum _{i=1}^{n}{w_{i}x_{i}}}{sum _{i=1}^{n}w_{i}}}.}

The weights wi{displaystyle w_{i}}
Truncated mean
Sometimes a set of numbers might contain outliers, i.e., data values which are much lower or much higher than the others.
Often, outliers are erroneous data caused by artifacts. In this case, one can use a truncated mean. It involves discarding given parts of the data at the top or the bottom end, typically an equal amount at each end and then taking the arithmetic mean of the remaining data. The number of values removed is indicated as a percentage of the total number of values.
Interquartile mean
The interquartile mean is a specific example of a truncated mean. It is simply the arithmetic mean after removing the lowest and the highest quarter of values.
- x¯=2n∑i=n4+134nxi{displaystyle {bar {x}}={frac {2}{n}};sum _{i={frac {n}{4}}+1}^{{frac {3}{4}}n}!!x_{i}}

assuming the values have been ordered, so is simply a specific example of a weighted mean for a specific set of weights.
Mean of a function
In some circumstances mathematicians may calculate a mean of an infinite (even an uncountable) set of values. This can happen when calculating the mean value yave{displaystyle y_{text{ave}}}
- yave(a,b)=1b−a∫abf(x)dx{displaystyle y_{text{ave}}(a,b)={frac {1}{b-a}}int limits _{a}^{b}!f(x),dx}

Care must be taken to make sure that the integral converges. But the mean may be finite even if the function itself tends to infinity at some points.
Mean of angles and cyclical quantities
Angles, times of day, and other cyclical quantities require modular arithmetic to add and otherwise combine numbers. In all these situations, there will not be a unique mean. For example, the times an hour before and after midnight are equidistant to both midnight and noon. It is also possible that no mean exists. Consider a color wheel -- there is no mean to the set of all colors. In these situations, you must decide which mean is most useful. You can do this by adjusting the values before averaging, or by using a specialized approach for the mean of circular quantities.
Fréchet mean
The Fréchet mean gives a manner for determining the "center" of a mass distribution on a surface or, more generally, Riemannian manifold. Unlike many other means, the Fréchet mean is defined on a space whose elements cannot necessarily be added together or multiplied by scalars.
It is sometimes also known as the Karcher mean (named after Hermann Karcher).
Other means
- Arithmetic-geometric mean
- Arithmetic-harmonic mean
- Cesàro mean
- Chisini mean
- Contraharmonic mean
- Elementary symmetric mean
- Geometric-harmonic mean
- Grand mean
- Heinz mean
- Heronian mean
- Identric mean
- Lehmer mean
- Logarithmic mean
- Moving average
- Neuman–Sándor mean
Root mean square (quadratic mean)
Rényi's entropy (a generalized f-mean)- Spherical mean
- Stolarsky mean
- Weighted geometric mean
- Weighted harmonic mean
Distribution of the sample mean
The arithmetic mean of a population, or population mean, is often denoted μ. The sample mean x¯{displaystyle {bar {x}}}
- Ex¯=μ{displaystyle operatorname {E} {bar {x}}=mu }

and the variance of the sample mean is
- var(x¯)=σ2n.{displaystyle operatorname {var} ({bar {x}})={frac {sigma ^{2}}{n}}.}

If the population is normally distributed, then the sample mean is normally distributed:
- x¯∼N{μ,σ2n}.{displaystyle {bar {x}}thicksim Nleft{mu ,{frac {sigma ^{2}}{n}}right}.}

If the population is not normally distributed, the sample mean is nonetheless approximately normally distributed if n is large and σ2/n < +∞. This follows from the central limit theorem.
See also
- Average
Central tendency
- Median
- Mode
- Descriptive statistics
- Kurtosis
- Law of averages
- Mean value theorem
- Median
- Mode (statistics)
- Summary statistics
- Taylor's law
References
^ Underhill, L.G.; Bradfield d. (1998) Introstat, Juta and Company Ltd. .mw-parser-output cite.citation{font-style:inherit}.mw-parser-output .citation q{quotes:"""""""'""'"}.mw-parser-output .citation .cs1-lock-free a{background:url("//upload.wikimedia.org/wikipedia/commons/thumb/6/65/Lock-green.svg/9px-Lock-green.svg.png")no-repeat;background-position:right .1em center}.mw-parser-output .citation .cs1-lock-limited a,.mw-parser-output .citation .cs1-lock-registration a{background:url("//upload.wikimedia.org/wikipedia/commons/thumb/d/d6/Lock-gray-alt-2.svg/9px-Lock-gray-alt-2.svg.png")no-repeat;background-position:right .1em center}.mw-parser-output .citation .cs1-lock-subscription a{background:url("//upload.wikimedia.org/wikipedia/commons/thumb/a/aa/Lock-red-alt-2.svg/9px-Lock-red-alt-2.svg.png")no-repeat;background-position:right .1em center}.mw-parser-output .cs1-subscription,.mw-parser-output .cs1-registration{color:#555}.mw-parser-output .cs1-subscription span,.mw-parser-output .cs1-registration span{border-bottom:1px dotted;cursor:help}.mw-parser-output .cs1-ws-icon a{background:url("//upload.wikimedia.org/wikipedia/commons/thumb/4/4c/Wikisource-logo.svg/12px-Wikisource-logo.svg.png")no-repeat;background-position:right .1em center}.mw-parser-output code.cs1-code{color:inherit;background:inherit;border:inherit;padding:inherit}.mw-parser-output .cs1-hidden-error{display:none;font-size:100%}.mw-parser-output .cs1-visible-error{font-size:100%}.mw-parser-output .cs1-maint{display:none;color:#33aa33;margin-left:0.3em}.mw-parser-output .cs1-subscription,.mw-parser-output .cs1-registration,.mw-parser-output .cs1-format{font-size:95%}.mw-parser-output .cs1-kern-left,.mw-parser-output .cs1-kern-wl-left{padding-left:0.2em}.mw-parser-output .cs1-kern-right,.mw-parser-output .cs1-kern-wl-right{padding-right:0.2em}
ISBN 0-7021-3838-X p. 181
^ Feller, William (1950). Introduction to Probability Theory and its Applications, Vol I. Wiley. p. 221. ISBN 0471257087.
^ Elementary Statistics by Robert R. Johnson and Patricia J. Kuby, p. 279
^ Schaum's Outline of Theory and Problems of Probability by Seymour Lipschutz and Marc Lipson, p. 141
^ "AP Statistics Review - Density Curves and the Normal Distributions". Retrieved 16 March 2015.
Statistics | |||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| |||||||||||||||||||||||||||
| |||||||||||||||||||||||||||
| |||||||||||||||||||||||||||
| |||||||||||||||||||||||||||
| |||||||||||||||||||||||||||
| |||||||||||||||||||||||||||
| |||||||||||||||||||||||||||
| |||||||||||||||||||||||||||


