計算複雜性理論
计算复杂性理论(Computational complexity theory)是理论计算机科学和数学的一个分支,它致力于将可计算问题根据它们本身的复杂性分类,以及将这些类别联系起来。一个可计算问题被认为是一个原则上可以用计算机解决的问题,亦即这个问题可以用一系列机械的数学步骤解决,例如算法。
如果一个问题的求解需要相当多的资源(无论用什么算法),则被认为是难解的。计算复杂性理论通过引入数学计算模型来研究这些问题以及定量计算解决问题所需的资源(时间和空间),从而将资源的确定方法正式化了。其他复杂性测度同样被运用,比如通信量(应用于通信复杂性),电路中门的数量(应用于电路复杂性)以及中央处理器的数量(应用于并行计算)。计算复杂性理论的一个作用就是确定一个能或不能被计算机求解的问题的所具有的实际限制。
在理论计算机科学领域,与此相关的概念有算法分析和可计算性理论。两者之间一个关键的区别是前者致力于分析用一个确定的算法来求解一个问题所需的资源量,而后者则是在更广泛意义上研究用所有可能的算法来解决相同问题。更精确地说,它尝试将问题分成能或不能在现有的适当受限的资源条件下解决这两类。相应地,在现有资源条件下的限制正是区分计算复杂性理论和可计算性理论的一个重要指标:后者关心的是何种问题原则上可以用算法解决。
目录
1 簡介
2 历史
3 基本概念和工具
3.1 计算模型与计算资源
3.2 判定性问题和可计算性
3.3 算法分析
3.4 复杂性类
3.5 归约
4 NP与P关系问题及相关理论
4.1 NP和P的定义
4.2 NP与P关系问题
4.3 NP完备理论
4.4 电路复杂性
4.5 其它NP与P关系问题相关的理论
5 理论与实践
6 参考文献
6.1 引用
6.2 来源
7 外部連結
8 參見
簡介
計算複雜性理論所研究的資源中最常見的是時間(要通過多少步演算才能解決問題)和空間(在解決問題時需要多少記憶體)。其他資源亦可考慮,例如在并行计算中,需要多少并行處理器才能解決問題。
時間複雜度是指在電腦科學與工程領域完成一個演算法所需要的時間,是衡量一個演算法優劣的重要參數。時間複雜度越小,說明該演算法效率越高,則該演算法越有價值。
空間複雜度是指電腦科學領域完成一個演算法所需要占用的存儲空間,一般是輸入參數的函數。它是演算法優劣的重要度量指標,一般來說,空間複雜度越小,演算法越好。我們假設有一個圖靈機來解決某一類語言的某一問題,設有X{displaystyle X}
複雜度理論和可计算性理论不同,可计算性理論的重心在於問題能否解決,不管需要多少資源。而复杂性理论作为计算理论的分支,某种程度上被认为和算法理论是一种“矛”与“盾”的关系,即算法理论专注于设计有效的算法,而复杂性理论专注于理解为什么对于某类问题,不存在有效的算法。
历史
在20世纪50年代,Trahtenbrot和Rabin的论文被认为是该领域最早的文献。而一般说来,被公认为奠定了计算复杂性领域基础的是Hartmanis和Stearns的1960年代的论文On the computational complexity of algorithms。在这篇论文中,作者引入了时间复杂性类TIME(f(n)){displaystyle {text{TIME}}(f(n))}
在此之后,许多研究者对复杂性理论作出了贡献。期间重要的发现包括:对随机算法的去随机化(derandomization)的研究,对近似算法的不可近似性(hardness of approximation)的研究,以及交互式证明系统理论和零知识证明(Zero-knowledge proof)等。特别的复杂性理论对近代密码学的影响非常显著,而最近,复杂性理论的研究者又进入了博弈论领域,并创立了“算法博弈论”(algorithmic game theory)这一分支。
基本概念和工具
计算模型与计算资源
计算复杂性理论的研究对象是算法在执行时所需的计算资源,而为了讨论这一点,我们必须假设算法是在某个计算模型上运行的。常讨论的计算模型包括图灵机(Turing machine)和电路(circuit),它们分别是一致性(uniform)和非一致性(non-uniform)计算模型的代表。而计算资源与计算模型是相关的,如对图灵机我们一般讨论的是时间、空间和随机源,而对电路我们一般讨论电路的大小。
由邱奇-图灵论题(Church-Turing thesis),所有的一致的计算模型与图灵机在多项式时间意义下是等价的。而由于我们一般将多项式时间作为有效算法的标志,该论题使得我们可以仅仅关注图灵机而忽略其它的计算模型。
判定性问题和可计算性
我们考虑对一个算法问题,什么样的回答是我们所需要的。比如搜索问题:给定数组A{displaystyle A}



自然的,我们会发现对于一般的算法问题A{displaystyle A}
在可计算性理论中,可以说明,判定型问题和搜索型问题在可计算性的意义下是等价的(见Decision problem)。而在计算复杂性中,Khuller和Vazirani在1990年代证明了在P≠NP的假设下,平面图4-着色问题的判定型问题是在P中的,而寻找其字典序第一的着色是NP难的。[1]
所以在可计算性理论中,只关注判定型问题是合理的。在计算复杂性理论中,虽然一些基本的复杂性类(如P,NP和PSPACE),以及一些基本的问题(P和NP关系问题等)是用判定型问题来定义的,但函数型问题复杂性类也被定义(如FP,FNP等),而且一些特别的函数型问题复杂性类,如TFNP,也正在逐渐受到关注。
算法分析
上面提到计算复杂性理论的研究对象是执行一项计算任务所用的资源,特别的,时间和空间是最重要的两项资源。
我们用时间作例子来讨论算法分析的一些基础知识。如果将输入的长度(设为n{displaystyle n}

以搜索这个计算任务为例。在搜索问题中,给定了一个具体的数s{displaystyle s}
如果我们假设s{displaystyle s}


而如果我们进一步假设A{displaystyle A}
复杂性类
将计算问题按照在不同计算模型下所需资源的不同予以分类,从而得到一个对算法问题“难度”的类别,就是复杂性理论中复杂性类概念的来源。例如一个问题如果在确定性图灵机上所需时间不会超过一个确定的多项式(以输入的长度为多项式的不定元),那么我们称这类问题的集合为P(polynomial time Turing machine)。而将前述定义中的“确定性图灵机”改为“不确定性图灵机”,那么所得到的问题集合为NP(non-deteministic polynomial time Turing machine)。类似的,设n{displaystyle n}

定义复杂性类问题的目的是为了将所有的算法问题进行分类,以确定当前算法的难度,和可能的前进方向。这是复杂性理论的一个主线之一:对算法问题进行抽象和分类。例如透过大O表达式,我们可以对忽略因计算模型不同而引入的常数因子。而第二个重要的理论假设,就是将多项式时间作为有效算法的标志(与之对应的是指数时间)。这样,复杂性类使得我们可以忽略多项式阶的不同而專注于多项式时间和指数时间的差别。(对多项式时间作为有效算法的标志这一点是有一定争议的,比如,如果算法的运行时间n10{displaystyle n^{10}}
归约
归约(reduction)是将不同算法问题建立联系的主要的技术手段,并且在某种程度上,定义了算法问题的相对难度。简单来说,假设我们有算法任务A{displaystyle A}



我们以点集覆盖问题(vertex cover)和独立集问题(independent set)为例来进行说明。这两个问题都是图论中的问题。假设给定了无向图G=(V,E){displaystyle G=(V,E)}







一个简单的观察即是:对G=(V,E){displaystyle G=(V,E)}

- 算法N{displaystyle N}
- 输入:给定无向图G=(V,E){displaystyle G=(V,E)}
- 输出:一个大小小于等于k{displaystyle k}
- 已知:算法M{displaystyle M}
- 输入:给定无向图G=(V,E){displaystyle G=(V,E)}
- 算法步骤:
- 对G{displaystyle G}
;
- 调用M{displaystyle M}
;
- 如果M{displaystyle M}
- 对G{displaystyle G}
可以看出若产生补图这一步是有效的,那么如果M{displaystyle M}
所以从归约的观点来看,下面的说法可以看作与“A{displaystyle A}
A{displaystyle A}- 存在通过查询B{displaystyle B}
NP与P关系问题及相关理论
计算复杂性理论最成功的成果之一是NP完备理论。通过该理论,我们可以理解为什么在程序设计与生产实践中遇到的很多问题至今没有找到多项式算法。而该理论更为计算复杂性中的核心问题:P与NP的关系问题指明了方向。
NP和P的定义
在上面我们已经知道,NP是指“在非确定性图灵机上有多项式时间算法的问题”的集合,而P是指“在确定性图灵机上有多项式时间算法的问题”的集合。这里我们都考虑的是判定型问题,即考虑一个语言L{displaystyle L}


举个例子,就是考虑完美匹配问题、点集覆盖问题和图不同构问题。这三个问题都有图论背影,问题的描述如下:
- 完美匹配问题:给定图G=(V,E){displaystyle G=(V,E)}
,使得对任意的v∈V{displaystyle vin V}
,存在唯一的e∈F,v∈e{displaystyle ein F,vin e}
;
- 点集覆盖问题:给定图G=(V,E){displaystyle G=(V,E)}
,使得对任意的e∈E{displaystyle ein E}
,存在v∈U,v∈e{displaystyle vin U,vin e}
,且|U|≤k{displaystyle |U|leq k}
;
- 图不同构问题:给定图G=(V,E),H=(U,F),|G|=|H|{displaystyle G=(V,E),H=(U,F),|G|=|H|}
。我们说G{displaystyle G}
是同构的,是指∃T:V→U{displaystyle exists T:Vrightarrow U}
,对任意的s,t∈V{displaystyle s,tin V}
,满足E(s,t)=F(T(s),T(t)){displaystyle E(s,t)=F(T(s),T(t))}
(这里我们把边集E{displaystyle E}
的映射)。图不同构是问对G{displaystyle G}
关于这三个问题,它们在复杂性理论中,目前的地位如下:
- 完美匹配问题:在P中。可以利用艾德蒙德算法得到O(VE){displaystyle O({sqrt {V}}E)}
运行时间的算法;
- 点集覆盖问题:在NP中,而不知道是否在P中。实际上,它是NP完备问题,给出它的多项式算法将意味着证明NP=P。它在NP中,原因是给定一个点的子集U⊂V{displaystyle Usubset V}
的大小很好验证。然后只需对每一条边e{displaystyle e}
,遍历U{displaystyle U}
,检查是否有v∈e{displaystyle vin e}
即可。运行时间至多为O(VE){displaystyle O(VE)}
;
- 图不同构问题:在AM中,而不知道是否在NP中。它之所以困难,一个直观的想法是:给定两个图G{displaystyle G}
是多项式大小。这里最直接的证据的定义,是说必须遍历所有的映射T:V→U{displaystyle T:Vrightarrow U}
,并对所有的映射验证是否满足同构的定义。而这样一个证据是指数大小的。
这样我们有了:在P中、在NP而不知道是不是在P中、在AM中而不知道是不是在NP中的三个问题。
NP与P关系问题
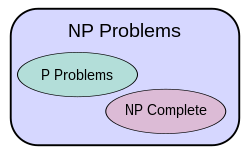
在P ≠ NP前提下复杂性类的关系图解。在该前提下,不在P也不是NP完备的问题的存在性由Ladner解决。[2]
由于在多项式时间可以判断x{displaystyle x}

关于NP与P关系问题最早发展出的理论是NP完备理论。我们在下面一节简单了解NP完备理论。
NP完备理论
由上面归约的知识我们知道,算法问题之间可以根据归约来定义相对的难度。即对问题A{displaystyle A}


这个问题乍看起来很不容易把握。因为这需要对所有的NP中的语言L,去找到一个L到A的归约算法。然而1970年代的由史蒂芬·库克和列昂尼德·列文分别发现的库克-列文定理,证明了布尔表达式(Boolean formula)的可满足性问题(SAT问题)是NP完备的。概括的说,他们证明了,有一个通用的过程对NP中任意语言在非确定性图灵机上运行历史用布尔表达式来编码,使得该布尔表达式是可满足的,当且仅当该运行历史是对给定输入,接受该输入的。这样,我们就有了第一个被证明是NP完备的问题。
在库克给出SAT问题是NP完备之后不久,理查德·卡普证明了21个图论、组合数学中常见的问题都是NP完备的。这赋予了NP完备问题在实践中的重要性。现在,已经有成千个在实践中遇到的算法问题被证明是NP完备的(参见NP完备问题列表),特别的有许多问题,如旅行商问题等的最优算法会带来很大的经济效益(旅行商问题的最优解可以给出最优的电路布线方案,而SAT的最优算法会促进程序验证等问题的进步)。由NP完备的定义,我们知道对这其中任何一个问题的多项式算法都将给出所有NP问题,也包括所有NP完备问题的多项式算法。然而尽管实际问题中遇到很多NP完备的问题,而且有很多问题在不同领域有着相当的重要性而被大量研究,至今,仍没有对NP完备问题的多项式算法,这是一些理论计算机科学家认为NP≠P的理由之一。
对NP和P关系问题,NP完备理论给出了如下的暗示:如果要证明NP=P,一个可能的方向是对NP完备问题给出多项式算法;如果要证明NP≠P,那么必然的一个结果是NP完备问题没有多项式算法。
电路复杂性
电路复杂性理论在1990年代以前,被众多研究者认为是解决NP与P关系问题的可能的途径之一。电路复杂性研究的对象是非一致性的计算模型电路,并考虑计算一个布尔函数所需的最小的电路的深度(depth)和大小(size)等资源。其中,大小为多项式大小的电路族可以计算的布尔函数被记为P/poly。可以证明,P包含在P/poly之中,而卡普-利普顿定理(Karp-Lipton theorem)表明若P/poly在NP之中,则多项式层级(polynomial hierarchy)将会坍缩至第二层,这是一个不大可能的结果。这两个结果结合起来表明,P/poly可以当作是分离NP与P的一个中间的工具,具体的途径就是证明任一个NP完全问题的电路大小的下界。在直观上说,电路复杂性也绕过了NP与P问题的第一个困难:相对化证明困难(relativizing proofs)。
在1980年代,电路复杂性途径取得了一系列的成功,其中包括奇偶性函数(Parity function)在AC0{displaystyle AC^{0}}
其它NP与P关系问题相关的理论
去随机化理论:包括伪随机数发生器dom generator)和extractor的构造等;
不可近似性:以PCP定理为基础,基于NP≠P和更强的唯一性游戏假设(Unique game conjecture),可以证明对一些问题不存在某近似比的近似算法;
理论与实践
计算复杂性的初衷是理解不同算法问题的难度,特别的是一些重要算法问题的困难性。为了确切的描述一个问题的困难性,计算复杂性的第一步抽象是认为多项式时间是有效的,非多项式时间是困难的。这基于指数函数增长速度的“违反直觉”的特性:如果一个算法的时间复杂性为2n{displaystyle 2^{n}}


然而多项式的指数很大的时候,算法在实践中也不能看作是有效的。如n10{displaystyle n^{10}}
参考文献
引用
^ Khuller, S. and Vazirani, V. V. 1991. Planar graph coloring is not self-reducible, assuming P≠NP . Theor. Comput. Sci. 88, 1 (Oct. 1991), 183-183.
^ Ladner, Richard E. On the structure of polynomial time reducibility (PDF). Journal of the ACM (JACM). 1975, 22 (1): 151–171. doi:10.1145/321864.321877.
来源
.mw-parser-output .refbegin{font-size:90%;margin-bottom:0.5em}.mw-parser-output .refbegin-hanging-indents>ul{list-style-type:none;margin-left:0}.mw-parser-output .refbegin-hanging-indents>ul>li,.mw-parser-output .refbegin-hanging-indents>dl>dd{margin-left:0;padding-left:3.2em;text-indent:-3.2em;list-style:none}.mw-parser-output .refbegin-100{font-size:100%}
- 書籍
Arora, Sanjeev; Barak, Boaz, Computational Complexity: A Modern Approach, Cambridge, 2009, ISBN 978-0-521-42426-4, Zbl 1193.68112
Downey, Rod; Fellows, Michael, Parameterized complexity, Berlin, New York: Springer-Verlag, 1999
Du, Ding-Zhu; Ko, Ker-I, Theory of Computational Complexity, John Wiley & Sons, 2000, ISBN 978-0-471-34506-0
- Template:Garey-Johnson
Goldreich, Oded, Computational Complexity: A Conceptual Perspective, Cambridge University Press, 2008
van Leeuwen, Jan (编), Handbook of theoretical computer science (vol. A): algorithms and complexity, MIT Press, 1990, ISBN 978-0-444-88071-0
Papadimitriou, Christos, Computational Complexity 1st, Addison Wesley, 1994, ISBN 0-201-53082-1
Sipser, Michael, Introduction to the Theory of Computation 2nd, USA: Thomson Course Technology, 2006, ISBN 0-534-95097-3
- 期刊文章
Khalil, Hatem; Ulery, Dana, A Review of Current Studies on Complexity of Algorithms for Partial Differential Equations, Proceedings of the annual conference on - ACM 76 (ACM '76 Proceedings of the 1976 Annual Conference), 1976: 197, doi:10.1145/800191.805573
Cook, Stephen, An overview of computational complexity (PDF), Commun. ACM (ACM), 1983, 26 (6): 400–408, ISSN 0001-0782, doi:10.1145/358141.358144
Fortnow, Lance; Homer, Steven, A Short History of Computational Complexity (PDF), Bulletin of the EATCS, 2003, 80: 95–133
Mertens, Stephan, Computational Complexity for Physicists, Computing in Science and Eng. (Piscataway, NJ, USA: IEEE Educational Activities Department), 2002, 4 (3): 31–47, ISSN 1521-9615, arXiv:cond-mat/0012185, doi:10.1109/5992.998639
外部連結
- The Complexity Zoo
參見
- 時間複雜度
- 遊戲複雜度
| ||||||||||||||||||||||||||||||

| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|


